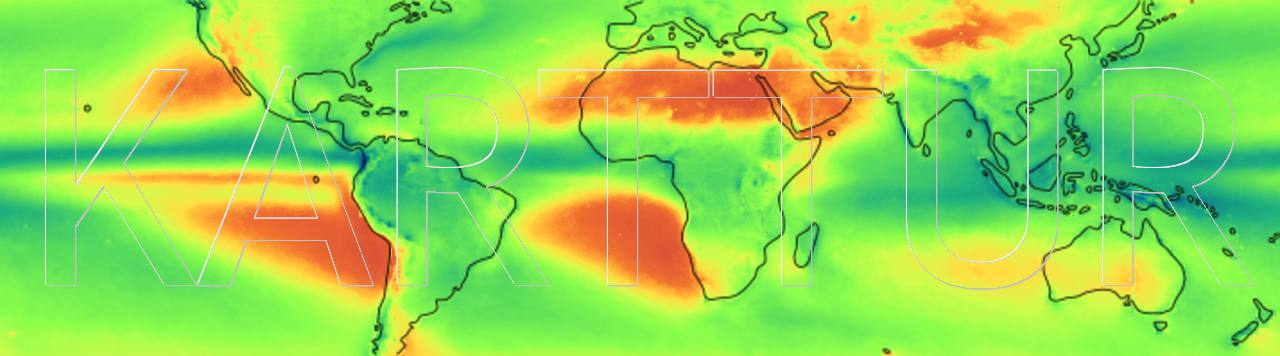
The Vertical Water Balance (VWB) is the local difference between precipitation and evapotranspiration. Regions with precipitation exceeding evapotranspiration are called humid, and areas where evapotranspiration exceed precipitation arid. Many regions have both wet and dry seasons, with humid conditions during the wet season and arid during the dry. Differentiating between humid and arid regions and seasons is important, for instance for understanding and predicting changes in water availability as a consequence of climate changes.
As explained in the post on Running processes you can create a project module for running specific tasks. The module below links to a single file (VWB_TRMM-vs-FAOrefevap.txt), that in turn links to a set of xml files. Running the module below will run all processes in the listed xml files.
At the very end of the post you find the process chain (i.e. the file VWB_TRMM-vs-FAOrefevap.txt) that will run the complete VWB calculation outlined below; including the time series analysis and export as images and animations.
Preprocessing
Before running the VWB you have to process the precipitation and evapotranspiration data to use as input. Accessing and organizing the TRMM and refET datasets are covered in two previous posts.
Before actually calculating the VWB you must fit the two datasets (rainfall and evapotranspiration) together. For the two datasets used here there are several issues that must be regarded for fitting the datasets:
Units must be the same (e.g mm/month)
The spatial extent must be the same
The spatial resolution must be the same
The regions of nodata should match
The TRMM data was converted to mm/month when imported to the Framework. The FAO reference evapotranspiration data were imported with the original scaling that represent mm/day times 10. Unless you already converted the FAO refET to mm/month, it must be done prior to calculating VWB.
The TRMM dataset covers a smaller spatial region (between 50 degrees latitude) and has a slightly coarser spatial resolution. The easiest way to fit the dataset is thus to reduce the spatial extent and spatial coverage of the FAO reference evapotranspiration. The TRMM data have estimated rainfall for all pixels, including over the oceans. The FAO reference evapotranspiration only covers land. Fitting the datasets should thus also include masking out the same land area.
Adjust the data units
Convert the reference evapotranspiration data in mm/day to mm/month by using the process convertdaytomonth.
The global refET dataset with monthly average evapotranspiration needs to be fitted to the TRMM dataset. In Karttur’s GeoImagine Framework the process for doing that is gdal_translateancillary. This process is just an interface to the GDAL utility gdal_translate. In the xml file below, the parameters define the translation by setting a pre-defined default region (‘trmm’) and the columns (‘xsize’) and rows (‘ysize’) spanning the default region:
The FAO refET data only cover land areas. To create a mask, use the transformed version of the refET that fits the TRMM region for defining a mask. You could use any of the months in the refET dataset for defining the mask but to make sure you mask out all regions you can also use all 12 months of refET to define the mask (just to make sure in case there are errors in the FAO refET nodata mask). The process createstaticmaskancillary will do it for you:
Note that the tractid is set to ‘karttur-trmm’, which is the region owned by the user karttur that is based on the default region trmm. When operating on the spatial data, the karttur region ‘karttur-trmm’ will use the default region (‘trmm’) for all naming. This prevents any user (including super users) to operate directly on any default region. A user can only operate on its own regions.
Apply mask
The mask you just created from the refET data must be applied to the complete time series of TRMM rainfall data. This is done with the process applystaticmaskancillary.
You should now have two time series covering the same spatial region, with the same spatial resolution and the same area of valid data: the dynamic TRMM precipitation dataset and the statistical FAO refET dataset. You can now calculate the Vertical Water Balance (VWB). As the refET dataset is a statistical seasonal dataset, the calculation of VWB equals removing the seasonal signal from the precipitation time series. As this is water balance data, it can be done in three ways: 1) as the complete difference, 2) only retaining rainfall surplus, or 3) only retaining rainfall deficit. In Karttur’s GeoImagine Framework you can do all three options using the process subtractseasonsancillary.
There are indications that climate change is causing a drying in dry regions/seasons and wetting in wet regions/seasons. To test that you can analyse the overall trends in VWB and compare it with the trends in humid and arid regions. Details about linear trend analysis in Karttur’s GeoImagine Framework is given in the post on SMAP processing. Time series linear trend analysis for ancillary data is done using the process trendtsancillary:
If you want to calculate the trends for other periods (than 1998-2017) you just alter the <period> tag in the xml file.
Change detection
You can use the results from the analysis of VWB trends to identify regions where the change has been significant, and how strong the changes have been. The process for that is signiftrendsancillary
If you want to create color maps/images and animations for presenting the VWB data you must create the required layout (see post on TRMM for more details).
Set scaling
Layout exports require scaling the original data to byte (0 - 255) range. Details on the scaling are given in the posts on SMAP and TRMM. The xml below calls the scaling definition process createscaling and sets the scaling of both the monthly and annual VWB layers, and all the layers produced as part of the trend analysis.
The VWB palettes below, created with the process addrasterpalette, are Karttur’s default palettes for VWB.
<
<?xml version='1.0' encoding='utf-8'?>
<palette>
<userproj userid = 'karttur' projectid = 'karttur' tractid= 'karttur' siteid = '*' plotid = '*' system = 'system'></userproj>
<!-- addrasterpalette VWB-->
<process processid = 'addrasterpalette'>
<overwrite>Y</overwrite>
<delete>N</delete>
<parameters compid= 'NA' palette = 'vwb'>
<setcolor id = '0' red = '103' green ='0' blue='31' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '25' red = '178' green ='24' blue='43' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '50' red = '214' green ='96' blue='77' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '75' red = '244' green ='165' blue='130' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '100' red = '253' green ='219' blue='199' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '125' red = '224' green ='224' blue='224' alpha ='0' label='max npv' hint='strongly significant positive trend' ></setcolor>
<setcolor id = '150' red = '202' green ='219' blue='253' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '175' red = '146' green ='197' blue='222' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '200' red = '67' green ='147' blue='195' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '225' red = '33' green ='102' blue='173' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '250' red = '5' green ='48' blue='97' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '253' red = '245' green ='237' blue='182' alpha ='0' label='unused' hint='NA' ></setcolor>
<setcolor id = '254' red = '32' green ='32' blue='32' alpha ='255' label='frame' hint='frame' ></setcolor>
<setcolor id = '255' red = '250' green ='250' blue='250' alpha ='255' label='255' hint='no data' ></setcolor>
</parameters>
</process>
<process processid = 'addrasterpalette'>
<overwrite>Y</overwrite>
<delete>N</delete>
<parameters compid= 'NA' palette = 'vwbinvert'>
<setcolor id = '250' red = '103' green ='0' blue='31' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '225' red = '178' green ='24' blue='43' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '200' red = '214' green ='96' blue='77' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '175' red = '244' green ='165' blue='130' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '150' red = '253' green ='219' blue='199' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '125' red = '224' green ='224' blue='224' alpha ='0' label='max npv' hint='strongly significant positive trend' ></setcolor>
<setcolor id = '100' red = '202' green ='219' blue='253' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '75' red = '146' green ='197' blue='222' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '50' red = '67' green ='147' blue='195' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '25' red = '33' green ='102' blue='173' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '0' red = '5' green ='48' blue='97' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '253' red = '245' green ='237' blue='182' alpha ='0' label='unused' hint='NA' ></setcolor>
<setcolor id = '254' red = '32' green ='32' blue='32' alpha ='255' label='frame' hint='frame' ></setcolor>
<setcolor id = '255' red = '250' green ='250' blue='250' alpha ='255' label='255' hint='no data' ></setcolor>
</parameters>
</process>
<process processid = 'addrasterpalette'>
<overwrite>Y</overwrite>
<delete>N</delete>
<parameters compid= 'NA' palette = 'VWBdeficit'>
<setcolor id = '0' red = '224' green ='224' blue='224' alpha ='0' label='max npv' hint='strongly significant positive trend' ></setcolor>
<setcolor id = '50' red = '253' green ='219' blue='199' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '100' red = '244' green ='165' blue='130' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '150' red = '214' green ='96' blue='77' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '200' red = '178' green ='24' blue='43' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '250' red = '103' green ='0' blue='31' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '253' red = '245' green ='237' blue='182' alpha ='0' label='dry (0)' hint='completely dry' ></setcolor>
<setcolor id = '254' red = '32' green ='32' blue='32' alpha ='255' label='frame' hint='frame' ></setcolor>
<setcolor id = '255' red = '0' green ='0' blue='0' alpha ='255' label='255' hint='no data' ></setcolor>
</parameters>
</process>
<process processid = 'addrasterpalette'>
<overwrite>Y</overwrite>
<delete>N</delete>
<parameters compid= 'NA' palette = 'VWBsurplus'>
<setcolor id = '0' red = '224' green ='224' blue='224' alpha ='0' label='max npv' hint='strongly significant positive trend' ></setcolor>
<setcolor id = '50' red = '202' green ='219' blue='253' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '100' red = '146' green ='197' blue='222' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '150' red = '67' green ='147' blue='195' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '200' red = '33' green ='102' blue='173' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '250' red = '5' green ='48' blue='97' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '253' red = '245' green ='237' blue='182' alpha ='0' label='dry (0)' hint='completely dry' ></setcolor>
<setcolor id = '254' red = '32' green ='32' blue='32' alpha ='255' label='frame' hint='frame' ></setcolor>
<setcolor id = '255' red = '0' green ='0' blue='0' alpha ='255' label='255' hint='no data' ></setcolor>
</parameters>
</process>
<process processid = 'addrasterpalette'>
<overwrite>Y</overwrite>
<delete>N</delete>
<parameters compid= 'NA' palette = 'VWBstd'>
<setcolor id = '0' red = '224' green ='224' blue='224' alpha ='0' label='max npv' hint='strongly significant positive trend' ></setcolor>
<setcolor id = '50' red = '202' green ='219' blue='253' alpha ='0' label='strongly neg' hint='strongly significant negative trend' ></setcolor>
<setcolor id = '100' red = '146' green ='197' blue='222' alpha ='0' label='neg' hint='significant negative' ></setcolor>
<setcolor id = '150' red = '67' green ='147' blue='195' alpha ='0' label='non significant' hint='non significant negative trend' ></setcolor>
<setcolor id = '200' red = '33' green ='102' blue='173' alpha ='0' label='no trend' hint='no trend' ></setcolor>
<setcolor id = '250' red = '5' green ='48' blue='97' alpha ='0' label='non significant' hint='non significant positive trend' ></setcolor>
<setcolor id = '253' red = '245' green ='237' blue='182' alpha ='0' label='dry (0)' hint='completely dry' ></setcolor>
<setcolor id = '254' red = '32' green ='32' blue='32' alpha ='255' label='frame' hint='frame' ></setcolor>
<setcolor id = '255' red = '0' green ='0' blue='0' alpha ='255' label='255' hint='no data' ></setcolor>
</parameters>
</process>
</palette>
Add movieclock
You do not need to add a special movieclock for VWB, the default movieclock works fine. But if you want to create a customised movieclock, the process is addmovieclock. The only parameter that is required is the name of the movieclock, all other parameters are set to default unless explicitly given as parameters (thus the movieclock added below will be identical to the default movieclock).
With the scaling and palettes defined, you can export any of the VWB layers created above.
Export monthly images
The full series of monthly VWB images is needed if you want to create an animation.
The following xml calls the process exporttobyteancillary and exports all the monthly VWB data, including the overall VWB, the humid VWB and the arid VWB.
All exports use the same process exporttobyteancillary, you just have to set the timestep and compostions to export all the statistical data, including the results of the trend analysis.
The process movieframeancillary converts the exported images (from previous step) to movie frames. The process is basically a dimension conversion that can also create an embossed text on the fly. For the process movieframeancillary to work you must have installed imagemagick as explained in another blogpost.
To run the process fully automated you must set the parameter asscript to False, otherwise you must manually execute the shell script file reported when the process comes to an end.
Note that because the three versions of VWB (the total VWB, suplus VWB and deficit VWB) were organized to be stored in the same directory (or folder) path, you can only create one animation at the time. If you want to create animations of all three versions you must delete the “movieframe” folder between each creation.
<?xml version='1.0' encoding='utf-8'?>
<movieframe>
<userproj userid = 'karttur' projectid = 'karttur' tractid= 'karttur-trmm' siteid = '*' plotid = '*' system = 'ancillary'></userproj>
<period startyear = "1998" endyear = "2018" endmonth='07' endday='31' timestep='M'></period>
<!-- Create movie frame -->
<process processid = 'movieframeancillary' version = '1.3'>
<overwrite>True</overwrite>
<parameters name = 'vwb' width = '800' crop='800,222,0,0' emboss='KARTTUR' embossdims='720,150' embossptsize='100' asscript='True'></parameters>
<srcpath volume = "travel" hdrfiletype = 'tif' datfiletype = 'tif'></srcpath>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<srccomp>
<trmm-fao-vwb id = 'layer1' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb" prefix = "trmm-fao-vwb" suffix = "v7-f-m">
</trmm-fao-vwb>
</srccomp>
</process>
<!-- Create movie frame surplus
If you want to create an animation from the VWB surplus timeseries
you must first make sure that the dstpath "movieframes" is empty,
i.e. you must first finish the movie for trmm-fao-vwb (above) and
delete all intermediate files (and only keep the final movie).
Otherwise the movie will include both trmm-fao-vwb and trmm-fao-vwb-surplus.
To create a movie form the surplus data, change processx to process below and
set process to processx for the process above.
-->
<processx processid = 'movieframeancillary' version = '1.3'>
<overwrite>False</overwrite>
<parameters name = 'vwb' width = '800' crop='800,222,0,0' emboss='KARTTUR' embossdims='720,150' embossptsize='100' asscript='True'></parameters>
<srcpath volume = "travel" hdrfiletype = 'tif' datfiletype = 'tif'></srcpath>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<srccomp>
<trmm-fao-vwb-surplus id = 'layer2' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb-surplus" prefix = "trmm-fao-vwb-surplus" suffix = "v7-f-m">
</trmm-fao-vwb-surplus>
</srccomp>
</processx>
<!-- Create movie frame deficit
If you want to create an animation from the VWB defiit timeseries
you must first make sure that the dstpath "movieframes" is empty,
see above.
-->
<processx processid = 'movieframeancillary' version = '1.3'>
<overwrite>False</overwrite>
<parameters name = 'vwb' width = '800' crop='800,222,0,0' emboss='KARTTUR' embossdims='720,150' embossptsize='100' asscript='True'></parameters>
<srcpath volume = "travel" hdrfiletype = 'tif' datfiletype = 'tif'></srcpath>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<srccomp>
<trmm-fao-vwb-deficit id = 'layer3' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb-deficit" prefix = "trmm-fao-vwb-deficit" suffix = "v7-f-m">
</trmm-fao-vwb-deficit>
</srccomp>
</processx>
</movieframe>
Create movie clock and animation
The process movieclockancillary first creates the movieclocks to combine with the movie frames from the previous step, and then creates the movie/animation itself. To run the process fully automated you must set the parameter asscript to False, otherwise you must manually execute the shell script files reported when the process comes to an end. By default the process will create script files so you must explicitly enter asscript="False" if you want the process to generate the complete animation on the fly.
<?xml version='1.0' encoding='utf-8'?>
<movieclock>
<userproj userid = 'karttur' projectid = 'karttur' tractid= 'karttur-trmm' siteid = '*' plotid = '*' system = 'ancillary'></userproj>
<period startyear = "1998" endyear = "2018" endmonth='07' endday='31' timestep='M'></period>
<!-- Create movie clock -->
<process processid = 'movieclockancillary' version = '1.3'>
<overwrite>False</overwrite>
<parameters name = 'trmm' width = '800' asscript='True'></parameters>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<dstcomp>
<trmm-fao-vwb id = 'layer1' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb" prefix = "trmm-fao-vwb" suffix = "v7-f-m">
</trmm-fao-vwb>
</dstcomp>
</process>
<!-- Create movie clock surplus
If you want to create an animation from the VWB surplus timeseries
you must first make sure that the dstpath "movieframes" is empty,
i.e. you must first finish the movie for trmm-fao-vwb (above) and
delete all intermediate files (and only keep the final movie).
Otherwise the movie will include both trmm-fao-vwb and trmm-fao-vwb-surplus.
To create a movie form the surplus data, change processx to process below and
set process to processx for the process above.
-->
<processx processid = 'movieclockancillary' version = '1.3'>
<overwrite>False</overwrite>
<parameters name = 'trmm' width = '800' asscript='True'></parameters>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<dstcomp>
<trmm-fao-vwb-surplus id = 'layer2' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb-surplus" prefix = "trmm-fao-vwb-surplus" suffix = "v7-f-m">
</trmm-fao-vwb-surplus>
</dstcomp>
</processx>
<!-- Create movie clock deficit
If you want to create an animation from the VWB defiit timeseries
you must first make sure that the dstpath "movieframes" is empty,
see above.
-->
<processx processid = 'movieclockancillary' version = '1.3'>
<overwrite>False</overwrite>
<parameters name = 'trmm' width = '800' asscript='True'></parameters>
<dstpath volume = "travel/movieclock" hdrfiletype = 'png' datfiletype = 'png'></dstpath>
<dstcomp>
<trmm-fao-vwb-deficit id = 'layer3' source = "trmm-vwb" product = "3b43" folder = "vwb" band = "trmm-fao-vwb-deficit" prefix = "trmm-fao-vwb-deficit" suffix = "v7-f-m">
</trmm-fao-vwb-deficit>
</dstcomp>
</processx>
</movieclock>
Process Chain
All of the above processes can be assembled into a single process chain as shown below. To run the process chain you just have to remove the comment marker “#” and run the Framework pointing at the text file with the process chain.
##### Vertical Water Balance using TRMM and FAO ref evap ######
#Uncomment the processes you want to run by removing the "#"
###################################
### Scaling, palette & legend ###
###################################
## Create scaling for VWB data ##
#VWB-0001_createscaling.xml
## Create the VWB palettes ##
#VWB-0002_createpalettes.xml
# Create legends for VWB ##
#VWB-0003_createlegends.xml
## Create TRMM movieclock ##
#VWB-0004_addmovieclock.xml
###################################
### Import ###
###################################
### NOTE: if you have access to VWB data processed from the Framework you can import it here
### Otherwise you need to follow the steps under # prepare data #. ###
## Update db with monthly VWB from existing Framework
#VWB-0190_udatedb.xml
###################################
### Prepare data ###
###################################
### NOTE: If you have imported VWB in the above # Import # step you can skip this (# Prepare data #) section. ###
## Convert FAO refet to mm/month
#VWB-0130_FAOrefet_convert_daytomonth.xml
## Translate FAO refet to spatial extent of TRMM ##
#VWB-0140_FAOrefet_translate_2_TRMM.xml
## create mask from FAO refet (land) that fits the TRMM data
#VWB-0160_FAOrefet_createmask.xml
## mask out land from TRMM (using the FAO refet mask)
#VWB-0170_TRMM-applymask.xml
###################################
### Time Series Processing ###
###################################
## Monthly vertical water balance ##
#VWB-0241_subtract_seasonal_trmm-refet.xml
## Resample VWB to annual ##
#VWB-0290_resample-2-annual.xml
###################################
### Time Series Analysis ###
###################################
## Estimate VWB annual trends (1998-2017 is for the complete timeseries, 2003-2016 for overlap with GRACE ##
#VWB-0310_trend_A_1998-2017.xml
#VWB-0310_trend_A_2003-2016.xml
## Identify regions with significant trends (1998-2017 is for the complete timeseries, 2003-2016 for overlap with GRACE ##
#VWB-0320_changes_A_1998-2017.xml
#VWB-0320_changes_A_2003-2016.xml
###################################
### Export media ###
###################################
## Export png images ##
#VWB-0900_ExporttoByte_M.xml
#VWB-0910_ExporttoByte_timespanA_1998-2017.xml
## Create TRMM movieframes (1998 to 2017)
## For fully automated processing you need to set parameter "asscript" to False
## If you set the parameter "asscript" to True (= default), you have to execute the shell script file reported by the process ##
#VWB-0950_movieframes_M.xml
## Create movieclock, the process creates two shell scripts that must by run ##
#VWB-0960_movieclock_M.xml